
Adversarial attacks on visual systems
Adversarial attacks mean crafting physical adversarial perturbations to fool image-based object detectors like Faster R-CNN, YOLO etc., In simple words, the attacker is trying to cheat the neural networks by creating optical illusions so that the network makes mistakes.
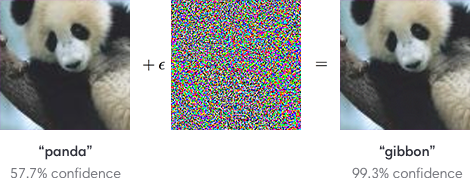
To a naked eye, the images above look like panda but adding an adversarial noise to the panda image can confuse the network and makes it classify the panda as gibbon easily.

Another example of it is someone can paint traffic signs so that it will confuse an automated car vision system and could lead to a potential accident. In the below picture, the right-side image is physically perturbed to be like a graffiti image on the left but it is classified by the network as a 45kmph speed sign.
These attacks are quite robust. Recent research has shown that anyone can print out adversarial examples and then take photos of them using their smartphone and use that to fool systems. The adversarial attacks can affect both supervised and reinforcement networks.
Working on this problem is very important as it is directly related to AI systems security and safety. Two prominent ways to deal with such attacks are adversarial training and defensive distillation.
Adversarial training: Here we generate a lot of adversarial examples and explicitly train the network on it so that our network would identify one when someone is trying to attack it.
Defensive distillation: Here we train the system on class probabilities instead of assigning them to fixed class outputs. So that the trained model will have a smooth surface in the directions where an attacker will typically target and makes it difficult for them to find which input tweaks will lead to incorrect categorization.
Even these specialized solutions can be broken by the attacker. One such example of a failed solution is gradient masking. The reason why it is difficult to tackle these adversarial attacks is the lack of theoretical modes which can explain the crafting process of such adversarial examples. The strategies that are designed are generally non-adaptive and can block only one or certain kinds of attacks.
To deal with this crucial problem of machine/ deep learning, the industry needs more research efforts and work closely with researchers.
Reference: Source: Explaining and Harnessing Adversarial Examples, Goodfellow et al, ICLR 2015.
Robust Physical-World Attacks on Deep Learning Visual Classification.
